How To Convert HTML To Formatted Plain Text
Simple removing of HTML tags with Regex.Replace method
Sometimes you want to remove tags from HTML and get only plain text. In general, this is simple task but there are few drawbacks in some scenarios. The simplest solution is to just remove all tags from given HTML without any formatting.
You can do it with code like this:
[ C# ]
public string RemoveHTMLTags(string HTMLCode)
{
return System.Text.RegularExpressions.Regex.Replace(
HTMLCode, "<[^>]*>", "");
}
[ VB.NET ]
Public Function RemoveHTMLTags(ByVal HTMLCode As String) As String
Return System.Text.RegularExpressions.Regex.Replace( _
HTMLCode, "<[^>]*>", "")
End Function
Better HTML to plain text conversion
Example above removes any tag from HTML. This is good enough in some scenarios, but there are some issues too:
- Text inside HEAD tag will be visible too,
- Empty spaces and new lines <br /> or paragraph <p> will be lost,
- Unwanted empty spaces that are invisible in HTML will show in plain text, and that will distract text even more,
- Special characters like & or © etc. will not be translated etc.
To solve all these problems, we need a little more processing of input HTML. Next function will provide better HTML to text conversion:
[ C# ]
// This function converts HTML code to plain text
// Any step is commented to explain it better
// You can change or remove unnecessary parts to suite your needs
public string HTMLToText(string HTMLCode)
{
// Remove new lines since they are not visible in HTML
HTMLCode = HTMLCode.Replace("\n", " ");
// Remove tab spaces
HTMLCode = HTMLCode.Replace("\t", " ");
// Remove multiple white spaces from HTML
HTMLCode = Regex.Replace(HTMLCode, "\\s+", " ");
// Remove HEAD tag
HTMLCode = Regex.Replace(HTMLCode, "<head.*?</head>", ""
, RegexOptions.IgnoreCase | RegexOptions.Singleline);
// Remove any JavaScript
HTMLCode = Regex.Replace(HTMLCode, "<script.*?</script>", ""
, RegexOptions.IgnoreCase | RegexOptions.Singleline);
// Replace special characters like &, <, >, " etc.
StringBuilder sbHTML = new StringBuilder(HTMLCode);
// Note: There are many more special characters, these are just
// most common. You can add new characters in this arrays if needed
string[] OldWords = {" ", "&", """, "<",
">", "®", "©", "•", "™"};
string[] NewWords = {" ", "&", "\"", "<", ">", "®", "©", "•", "™"};
for(int i = 0; i < OldWords.Length; i++)
{
sbHTML.Replace(OldWords[i], NewWords[i]);
}
// Check if there are line breaks (<br>) or paragraph (<p>)
sbHTML.Replace("<br>", "\n<br>");
sbHTML.Replace("<br ", "\n<br ");
sbHTML.Replace("<p ", "\n<p ");
// Finally, remove all HTML tags and return plain text
return System.Text.RegularExpressions.Regex.Replace(
sbHTML.ToString(), "<[^>]*>", "");
}
[ VB.NET ]
' This function converts HTML code to plain text
' Any step is commented to explain it better
' You can change or remove unnecessary parts to suite your needs
Public Function HTMLToText(ByVal HTMLCode As String) As String
' Remove new lines since they are not visible in HTML
HTMLCode = HTMLCode.Replace("\n", " ")
' Remove tab spaces
HTMLCode = HTMLCode.Replace("\t", " ")
' Remove multiple white spaces from HTML
HTMLCode = Regex.Replace(HTMLCode, "\\s+", " ")
' Remove HEAD tag
HTMLCode = Regex.Replace(HTMLCode, "<head.*?</head>", "" _
, RegexOptions.IgnoreCase Or RegexOptions.Singleline)
' Remove any JavaScript
HTMLCode = Regex.Replace(HTMLCode, "<script.*?</script>", "" _
, RegexOptions.IgnoreCase Or RegexOptions.Singleline)
' Replace special characters like &, <, >, " etc.
Dim sbHTML As StringBuilder = New StringBuilder(HTMLCode)
' Note: There are many more special characters, these are just
' most common. You can add new characters in this arrays if needed
Dim OldWords() As String = {" ", "&", """, "<", _
">", "®", "©", "•", "™"}
Dim NewWords() As String = {" ", "&", """", "<", ">", "®", "©", "•", "™"}
For i As Integer = 0 To i < OldWords.Length
sbHTML.Replace(OldWords(i), NewWords(i))
Next i
' Check if there are line breaks (<br>) or paragraph (<p>)
sbHTML.Replace("<br>", "\n<br>")
sbHTML.Replace("<br ", "\n<br ")
sbHTML.Replace("<p ", "\n<p ")
' Finally, remove all HTML tags and return plain text
Return System.Text.RegularExpressions.Regex.Replace( _
sbHTML.ToString(), "<[^>]*>", "")
End Function
HTML to plain text ASP.NET example
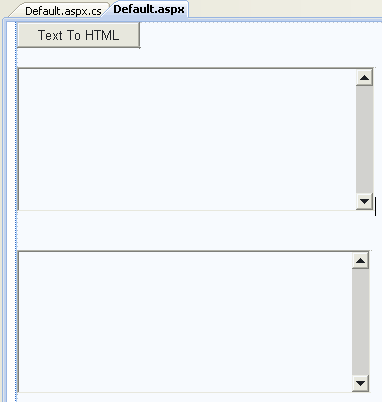
Now, we can build an example that convert HTML to plain text. Create new web page with one Button control and two TextBox controls, like on image bellow:
First TextBox control ID will be tbHTML and second TextBox control ID set to tbPlainText. On button's click write this code:
[ C# ]
protected void btnTextToHTML_Click(object sender, EventArgs e)
{
tbPlainText.Text = HTMLToText(tbHTML.Text);
}
[ VB.NET ]
Protected Sub btnTextToHTML_Click(ByVal sender As Object, ByVal e As System.EventArgs) Handles btnTextToHTML.Click
tbPlainText.Text = HTMLToText(tbHTML.Text)
End Sub
Please note that HTML is considered as dangerous input. To make this example works you need to add ValidateRequest="false" part to @Page directive. Otherwise, you'll get an error "A potentially dangerous Request.Form value was detected from the client...)" like on next image.
When you set ValidateRequest parameter to false, you can run an example. Place some HTML code to tbHTML TextBox control and click on Button. Plain text will be extracted from given HTML and shown in tbPlainText.
As you see, there are few different options when converting HTML to plain text. Depending of your needs you can only remove tags or provide additional formatting. Suggested HTMLToText function is not perfect. You can make it better if you add all symbols or add line breaks for new table rows, or add tab spaces for evey new table cell etc. Be aware that with every new option included this function becomes slower. If you overdo the conversion could be unsatisfactory, especially if you have large HTML files. Happy coding!
Tutorial toolbar: Tell A Friend | Add to favorites | Feedback |
|